
flink介绍、反压原理、内存管理、对比spark、flink的生态和应用场景以及未来
1. 为什么要学习Flink
这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop、Storm,以及后来的 Spark,他们都有着各自专注的应用场景。Spark 掀开了内存计算的先河,也以内存为赌注,赢得了内存计算的飞速发展。Spark 的火热或多或少的掩盖了其他分布式计算的系统身影。就像 Flink,也就在这个时候默默的发展着。
在国外一些社区,有很多人将大数据的计算引擎分成了 4 代,当然,也有很多人不会认同。我们先姑且这么认为和讨论。
首先第一代的计算引擎,无疑就是 Hadoop 承载的 MapReduce。这里大家应该都不会对 MapReduce 陌生,它将计算分为两个阶段,分别为 Map 和 Reduce。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。
由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如 Tez 以及更上层的 Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。
接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。在这里,很多人也会认为第三代计算引擎也能够很好的运行批处理的 Job。
随着第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和 SQL 等的支持。Flink 的诞生就被归在了第四代。这应该主要表现在 Flink 对流计算的支持,以及更一步的实时性。当然 Flink 也可以支持 Batch 的任务,以及 DAG 的运算。
2.什么是Flink
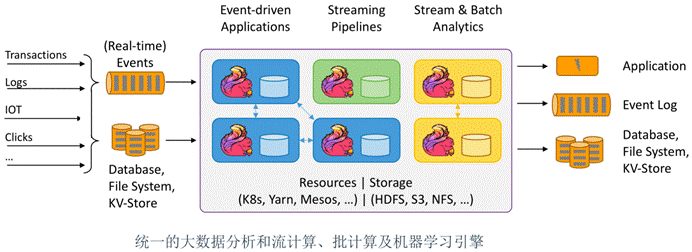
Apache Flink是一个分布式大数据处理引擎,可对有界数据流和无界数据流进行有状态计算。 可部署在各种集群环境,对各种大小的数据规模进行快速计算。
什么是有界数据流和无界数据流?
- 无界流有一个开始但没有定义的结束。它们不会在生成时终止并提供数据。必须持续处理无界流,即必须在摄取事件后立即处理事件。无法等待所有输入数据到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)摄取事件。
- 有界流具有定义的开始和结束。可以在执行任何计算之前通过摄取所有数据来处理有界流。处理有界流不需要有序摄取,因为可以始终对有界数据集进行排序。有界流的处理也称为批处理。
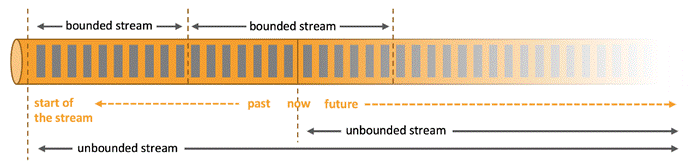
Apache Flink擅长处理无界和有界数据集。精确控制时间和状态使Flink的运行时能够在无界流上运行任何类型的应用程序。有界流由算法和数据结构内部处理,这些算法和数据结构专门针对固定大小的数据集而设计,从而产生出色的性能。
3.Flink历史
Flink诞生于欧洲的一个大数据研究项目,原名 StratoSphere。该项目是柏林工业大学的一个研究性项目,早期专注于批计算。2014 年,StratoSphere 项目中的核心成员孵化出 Flink,并在同年将 Flink 捐赠 Apache,后来 Flink 顺利成为 Apache 的顶级大数据项目。同时 Flink 计算的主流方向被定位为流计算,即用流式计算来做所有大数据 的计算工作,这就是 Flink 技术诞生的背景。

Apache Flink起了个大早,赶了个晚集,在 2015 年突然出现在大数据舞台,然后似乎在一夜之间从一个无人所知的系统迅速转变为人人皆知的流式处理引擎。
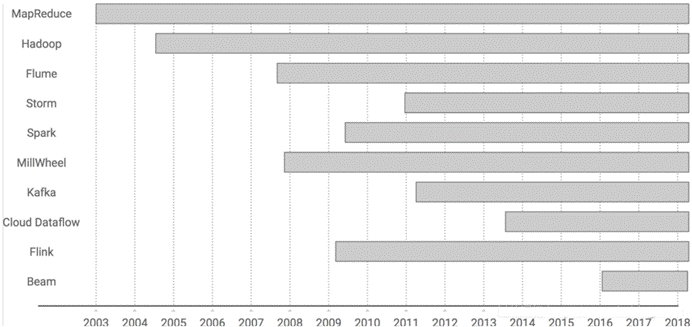
2014 年 Flink 作为主攻流计算的大数据引擎开始在开源大数据行业内崭露头角。区别于 Storm、Spark Streaming 以及其他流式计算引擎的是:它不仅是一个高吞吐、低延迟的 计算引擎,同时还提供很多高级功能。比如它提供有状态的计算,支持状态管理,支持强一致性的数据语义以及支持 Event Time,WaterMark 对消息乱序的处理等
2015 年是流计算百花齐放的时代,各个流计算框架层出不穷。Storm, JStorm, Heron, Flink, Spark Streaming, Google Dataflow (后来的 Beam) 等等。其中 Flink 的一致性语义和最接近 Dataflow 模型的开源实现,使其成为流计算框架中最耀眼的一颗。也许这也 是阿里看中 Flink的原因,并决心投入重金去研究基于 Flink的 Blink框架。
然后就有了阿里爸爸买买买

4.Flink的特点
支持java(主)和 scala api(真香)
流(dataStream)批(dataSet)一体化
支持事件处理和无序处理通过DataStream API,基于DataFlow数据流模型
在不同的时间语义(事件时间,摄取时间、处理时间)下支持灵活的窗口(时间,滑动、翻滚,会话,自定义触发器)
支持有状态计算的Exactly-once(仅处理一次)容错保证
支持基于轻量级分布式快照checkpoint机制实现的容错
支持savepoints 机制,一般手动触发,在升级应用或者处理历史数据是能够做到无状态丢失和最小停机时间
兼容hadoop的mapreduce,集成YARN,HDFS,Hbase 和其它hadoop生态系统的组件
支持大规模的集群模式,支持yarn、Mesos。可运行在成千上万的节点上
在dataSet(批处理)API中内置支持迭代程序
图处理(批) 机器学习(批) 复杂事件处理(流)
自动反压机制
高效的自定义内存管理
健壮的切换能力在in-memory和out-of-core中
5.finlk的反压原理
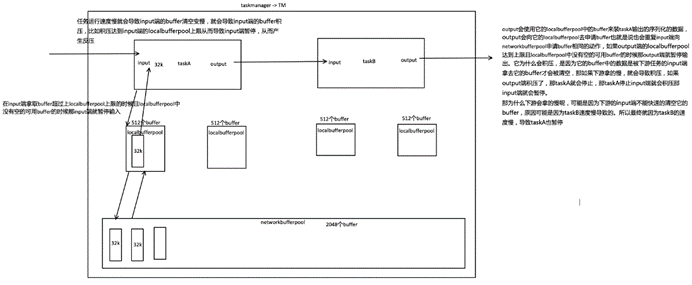
如下图所示展示了 Flink 在网络传输场景下的内存管理。网络上传输的数据会写到 Task 的 InputGate(IG) 中,经过 Task 的处理后,再由 Task 写到 ResultPartition(RS) 中。每个 Task 都包括了输入和输入,输入和输出的数据存在 Buffer 中(都是字节数据)。Buffer 是 MemorySegment 的包装类。
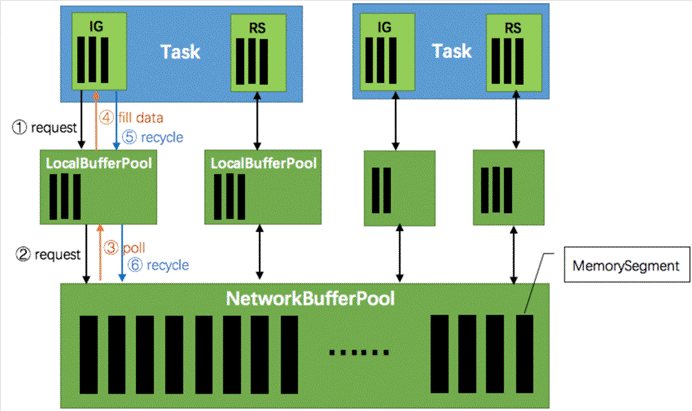
根据配置,Flink 会在 NetworkBufferPool 中生成一定数量(默认2048)的内存块 MemorySegment,内存块的总数量就代表了网络传输中所有可用的内存。NetworkEnvironment 和 NetworkBufferPool 是 Task 之间共享的,每个节点(TaskManager)只会实例化一个。
Task 线程启动时,会向 NetworkEnvironment 注册,NetworkEnvironment 会为 Task 的 InputGate(IG)和 ResultPartition(RP) 分别创建一个 LocalBufferPool(缓冲池)并设置可申请的 MemorySegment(内存块)数量。IG 对应的缓冲池初始的内存块数量与 IG 中 InputChannel 数量一致,RP 对应的缓冲池初始的内存块数量与 RP 中的 ResultSubpartition 数量一致。不过,每当创建或销毁缓冲池时,NetworkBufferPool 会计算剩余空闲的内存块数量,并平均分配给已创建的缓冲池。注意,这个过程只是指定了缓冲池所能使用的内存块数量,并没有真正分配内存块,只有当需要时才分配。为什么要动态地为缓冲池扩容呢?因为内存越多,意味着系统可以更轻松地应对瞬时压力(如GC),不会频繁地进入反压状态,所以我们要利用起那部分闲置的内存块。
在 Task 线程执行过程中,当 Netty 接收端收到数据时,为了将 Netty 中的数据拷贝到 Task 中,InputChannel(实际是 RemoteInputChannel)会向其对应的缓冲池申请内存块(上图中的①)。如果缓冲池中也没有可用的内存块且已申请的数量还没到池子上限,则会向 NetworkBufferPool 申请内存块(上图中的②)并交给 InputChannel 填上数据(上图中的③和④)。如果缓冲池已申请的数量达到上限了呢?或者 NetworkBufferPool 也没有可用内存块了呢?这时候,Task 的 Netty Channel 会暂停读取,上游的发送端会立即响应停止发送,拓扑会进入反压状态。当 Task 线程写数据到 ResultPartition 时,也会向缓冲池请求内存块,如果没有可用内存块时,会阻塞在请求内存块的地方,达到暂停写入的目的。
当一个内存块被消费完成之后(在输入端是指内存块中的字节被反序列化成对象了,在输出端是指内存块中的字节写入到 Netty Channel 了),会调用 Buffer.recycle() 方法,会将内存块还给 LocalBufferPool (上图中的⑤)。如果LocalBufferPool中当前申请的数量超过了池子容量(由于上文提到的动态容量,由于新注册的 Task 导致该池子容量变小),则LocalBufferPool会将该内存块回收给 NetworkBufferPool(上图中的⑥)。如果没超过池子容量,则会继续留在池子中,减少反复申请的开销。
反压的过程
下面这张图简单展示了两个 Task 之间的数据传输以及 Flink 如何感知到反压的:
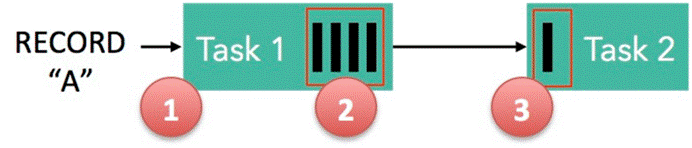
记录“A”进入了 Flink 并且被 Task 1 处理。(这里省略了 Netty 接收、反序列化等过程)
记录被序列化到 buffer 中。
该 buffer 被发送到 Task 2,然后 Task 2 从这个 buffer 中读出记录。
不要忘了:记录能被 Flink 处理的前提是,必须有空闲可用的 Buffer
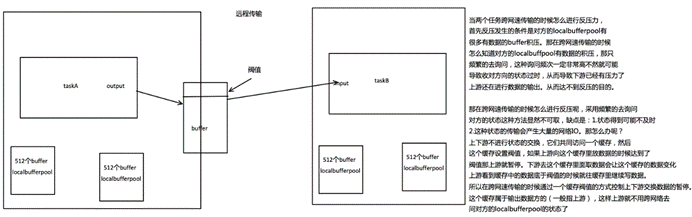
结合上面两张图看:Task 1 在输出端有一个相关联的 LocalBufferPool(称缓冲池1),Task 2 在输入端也有一个相关联的 LocalBufferPool(称缓冲池2)。如果缓冲池1中有空闲可用的 buffer 来序列化记录 “A”,我们就序列化并发送该 buffer。
这里我们需要注意两个场景:
- 本地传输:如果 Task 1 和 Task 2 运行在同一个 worker 节点(TaskManager),该 buffer 可以直接交给下一个 Task。一旦 Task 2 消费了该 buffer,则该 buffer 会被缓冲池1回收。如果 Task 2 的速度比 1 慢,那么 buffer 回收的速度就会赶不上 Task 1 取 buffer 的速度,导致缓冲池1无可用的 buffer,Task 1 等待在可用的 buffer 上。最终形成 Task 1 的降速。
- 远程传输:如果 Task 1 和 Task 2 运行在不同的 worker 节点上,那么 buffer 会在发送到网络(TCP Channel)后被回收。在接收端,会从 LocalBufferPool 中申请 buffer,然后拷贝网络中的数据到 buffer 中。如果没有可用的 buffer,会停止从 TCP 连接中读取数据。在输出端,通过 Netty 的水位值机制(可配置)来保证不往网络中写入太多数据。如果网络中的数据(Netty输出缓冲中的字节数)超过了高水位值,我们会等到其降到低水位值以下才继续写入数据。这保证了网络中不会有太多的数据。如果接收端停止消费网络中的数据(由于接收端缓冲池没有可用 buffer),网络中的缓冲数据就会堆积,那么发送端也会暂停发送。另外,这会使得发送端的缓冲池得不到回收,writer 阻塞在向 LocalBufferPool 请求 buffer,阻塞了 writer 往 ResultSubPartition 写数据。
这种固定大小缓冲池就像阻塞队列一样,保证了 Flink 有一套健壮的反压机制,使得 Task 生产数据的速度不会快于消费的速度。我们上面描述的这个方案可以从两个 Task 之间的数据传输自然地扩展到更复杂的 pipeline 中,保证反压机制可以扩散到整个 pipeline。
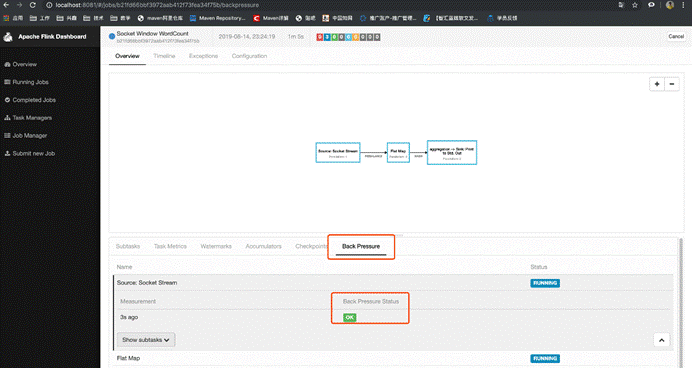
反压监控
Flink 的实现中,只有当 Web 页面切换到某个 Job 的 Backpressure 页面,才会对这个 Job 触发反压检测,因为反压检测还是挺昂贵的。JobManager 会通过 Akka 给每个 TaskManager 发送TriggerStackTraceSample消息。默认情况下,TaskManager 会触发100次 stack trace 采样,每次间隔 50ms(也就是说一次反压检测至少要等待5秒钟)。并将这 100 次采样的结果返回给 JobManager,由 JobManager 来计算反压比率(反压出现的次数/采样的次数),最终展现在 UI 上。UI 刷新的默认周期是一分钟,目的是不对 TaskManager 造成太大的负担。
6.flink的内存管理
基于 JVM 的数据分析引擎都需要面对将大量数据存到内存中,这就不得不面对 JVM 存在的几个问题:
- Java 对象存储密度低。一个只包含 boolean 属性的对象占用了16个字节内存:对象头占了8个,boolean 属性占了1个,对齐填充占了7个。而实际上只需要一个bit(1/8字节)就够了。
- Full GC 会极大地影响性能,尤其是为了处理更大数据而开了很大内存空间的JVM来说,GC 会达到秒级甚至分钟级。
- OOM 问题影响稳定性。OutOfMemoryError是分布式计算框架经常会遇到的问题,当JVM中所有对象大小超过分配给JVM的内存大小时,就会发生OutOfMemoryError错误,导致JVM崩溃,分布式框架的健壮性和性能都会受到影响。
所以目前,越来越多的大数据项目开始自己管理JVM内存了,为的就是获得像 C 一样的性能以及避免 OOM 的发生,Flink 是如何解决上面的问题的,主要内容包括内存管理、定制的序列化工具、缓存友好的数据结构和算法、堆外内存、JIT编译优化等。
积极的内存管理
Flink 并不是将大量对象存在堆上,而是将对象都序列化到一个预分配的内存块上,这个内存块叫做 MemorySegment,它代表了一段固定长度的内存(默认大小为 32KB),也是 Flink 中最小的内存分配单元,并且提供了非常高效的读写方法。你可以把 MemorySegment 想象成是为 Flink 定制的 java.nio.ByteBuffer。它的底层可以是一个普通的 Java 字节数组(byte[]),也可以是一个申请在堆外的 ByteBuffer。每条记录都会以序列化的形式存储在一个或多个MemorySegment中。
Flink 中的 Worker 名叫 TaskManager,是用来运行用户代码的 JVM 进程。TaskManager 的堆内存主要被分成了三个部分
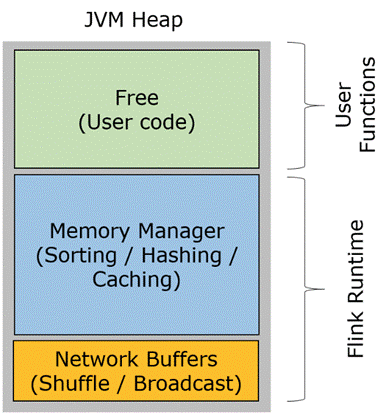
l Network Buffers: 一定数量的32KB大小的 buffer,主要用于数据的网络传输。在 TaskManager 启动的时候就会分配。默认数量是 2048 个,可以通过 taskmanager.network.numberOfBuffers 来配置。
l Memory Manager Pool: 这是一个由 MemoryManager 管理的,由众多MemorySegment组成的超大集合。Flink 中的算法(如 sort/shuffle/join)会向这个内存池申请 MemorySegment,将序列化后的数据存于其中,使用完后释放回内存池。默认情况下,池子占了堆内存的 70% 的大小。
l Remaining (Free) Heap: 这部分的内存是留给用户代码以及 TaskManager 的数据结构使用的。因为这些数据结构一般都很小,所以基本上这些内存都是给用户代码使用的。从GC的角度来看,可以把这里看成的新生代,也就是说这里主要都是由用户代码生成的短期对象。
注意:Memory Manager Pool 主要在Batch模式下使用。在Steaming模式下,该池子不会预分配内存,也不会向该池子请求内存块。也就是说该部分的内存都是可以给用户代码使用的。不过社区是打算在 Streaming 模式下也能将该池子利用起来。
序列化方法
Flink 采用类似 DBMS 的 sort 和 join 算法,直接操作二进制数据,从而使序列化/反序列化带来的开销达到最小。如果需要处理的数据超出了内存限制,则会将部分数据存储到硬盘上。下图描述了 Flink 如何存储序列化后的数据到内存块中,以及在需要的时候如何将数据存储到磁盘上。
从上面我们能够得出 Flink 积极的内存管理以及直接操作二进制数据有以下几点好处:
减少GC压力。显而易见,因为所有常驻型数据都以二进制的形式存在 Flink 的MemoryManager中,这些MemorySegment一直呆在老年代而不会被GC回收。其他的数据对象基本上是由用户代码生成的短生命周期对象,这部分对象可以被 Minor GC 快速回收。只要用户不去创建大量类似缓存的常驻型对象,那么老年代的大小是不会变的,Major GC也就永远不会发生。从而有效地降低了垃圾回收的压力。另外,这里的内存块还可以是堆外内存,这可以使得 JVM 内存更小,从而加速垃圾回收。
避免了OOM。所有的运行时数据结构和算法只能通过内存池申请内存,保证了其使用的内存大小是固定的,不会因为运行时数据结构和算法而发生OOM。在内存吃紧的情况下,算法(sort/join等)会高效地将一大批内存块写到磁盘,之后再读回来。因此,OutOfMemoryErrors可以有效地被避免。
节省内存空间。Java 对象在存储上有很多额外的消耗(如上一节所谈)。如果只存储实际数据的二进制内容,就可以避免这部分消耗。
高效的二进制操作 & 缓存友好的计算。二进制数据以定义好的格式存储,可以高效地比较与操作。另外,该二进制形式可以把相关的值,以及hash值,键值和指针等相邻地放进内存中。这使得数据结构可以对高速缓存更友好,可以从 L1/L2/L3 缓存获得性能的提升。
为 Flink 量身定制的序列化框架
目前 Java 生态圈提供了众多的序列化框架:Java serialization, Kryo, Apache Avro 等等。但是 Flink 实现了自己的序列化框架。因为在 Flink 中处理的数据流通常是同一类型,由于数据集对象的类型固定,对于数据集可以只保存一份对象Schema信息,节省大量的存储空间。同时,对于固定大小的类型,也可通过固定的偏移位置存取。当我们需要访问某个对象成员变量的时候,通过定制的序列化工具,并不需要反序列化整个Java对象,而是可以直接通过偏移量,只是反序列化特定的对象成员变量。如果对象的成员变量较多时,能够大大减少Java对象的创建开销,以及内存数据的拷贝大小。
Flink支持的数据类型
Flink支持任意的Java或是Scala类型。Flink 在数据类型上有很大的进步,不需要实现一个特定的接口(像Hadoop中的org.apache.hadoop.io.Writable),Flink 能够自动识别数据类型。Flink 通过 Java Reflection 框架分析。基于 Java 的 Flink 程序 UDF (User Define Function)的返回类型的类型信息,通过 Scala Compiler 分析基于 Scala 的 Flink 程序 UDF 的返回类型的类型信息。类型信息由 TypeInformation 类表示,TypeInformation 支持以下几种类型:
l BasicTypeInfo: 任意Java 基本类型(装箱的)或 String 类型。
l BasicArrayTypeInfo: 任意Java基本类型数组(装箱的)或 String 数组。
l WritableTypeInfo: 任意 Hadoop Writable 接口的实现类。
l TupleTypeInfo: 任意的 Flink Tuple 类型(支持Tuple1 to Tuple25)。Flink tuples 是固定长度固定类型的Java Tuple实现。
l CaseClassTypeInfo: 任意的 Scala CaseClass(包括 Scala tuples)。
l PojoTypeInfo: 任意的 POJO (Java or Scala),例如,Java对象的所有成员变量,要么是 public 修饰符定义,要么有 getter/setter 方法。
l GenericTypeInfo: 任意无法匹配之前几种类型的类。
前六种数据类型基本上可以满足绝大部分的Flink程序,针对前六种类型数据集,Flink皆可以自动生成对应的TypeSerializer,能非常高效地对数据集进行序列化和反序列化。对于最后一种数据类型,Flink会使用Kryo进行序列化和反序列化。每个TypeInformation中,都包含了serializer,类型会自动通过serializer进行序列化,然后用Java Unsafe接口写入MemorySegments。对于可以用作key的数据类型,Flink还同时自动生成TypeComparator,用来辅助直接对序列化后的二进制数据进行compare、hash等操作。对于 Tuple、CaseClass、POJO 等组合类型,其TypeSerializer和TypeComparator也是组合的,序列化和比较时会委托给对应的serializers和comparators。如下图展示 一个内嵌型的Tuple3<Integer,Double,Person> 对象的序列化过程。
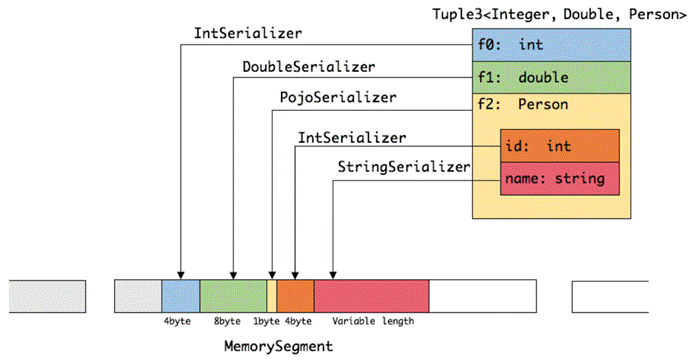
可以看出这种序列化方式存储密度是相当紧凑的。其中 int 占4字节,double 占8字节,POJO多个一个字节的header,PojoSerializer只负责将header序列化进去,并委托每个字段对应的serializer对字段进行序列化。
Flink 的类型系统可以很轻松地扩展出自定义的TypeInformation、Serializer以及Comparator,来提升数据类型在序列化和比较时的性能。
排序
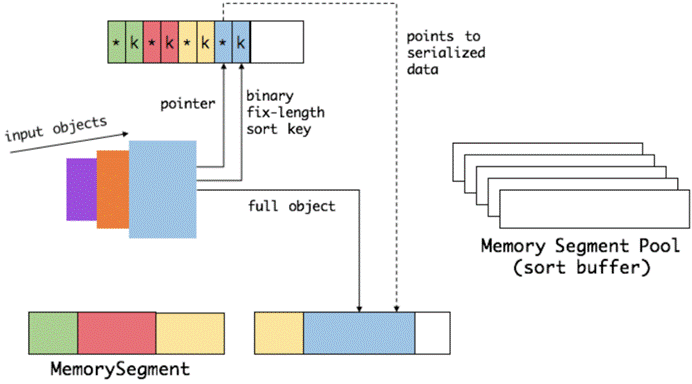
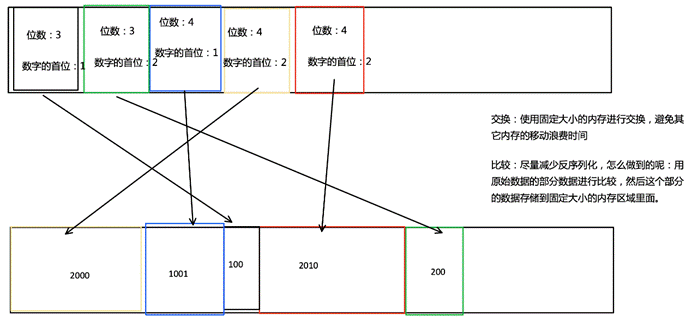
我们会把 sort buffer 分成两块区域。一个区域是用来存放所有对象完整的二进制数据。另一个区域用来存放指向完整二进制数据的指针以及定长的序列化后的key(key+pointer)。如果需要序列化的key是个变长类型,如String,则会取其前缀序列化。当一个对象要加到 sort buffer 中时,它的二进制数据会被加到第一个区域,指针(可能还有key)会被加到第二个区域。
将实际的数据和指针加定长key分开存放有两个目的。第一,交换定长块(key+pointer)更高效,不用交换真实的数据也不用移动其他key和pointer。第二,这样做是缓存友好的,因为key都是连续存储在内存中的,这大大提高了缓存命中率。
排序的关键是比大小和交换。Flink 中,会先用 key 比大小,这样就可以直接用二进制的key比较而不需要反序列化出整个对象。因为key是定长的,所以如果key相同(或者没有提供二进制key),那就必须将真实的二进制数据反序列化出来,然后再做比较。之后,只需要交换key+pointer就可以达到排序的效果,真实的数据不用移动。
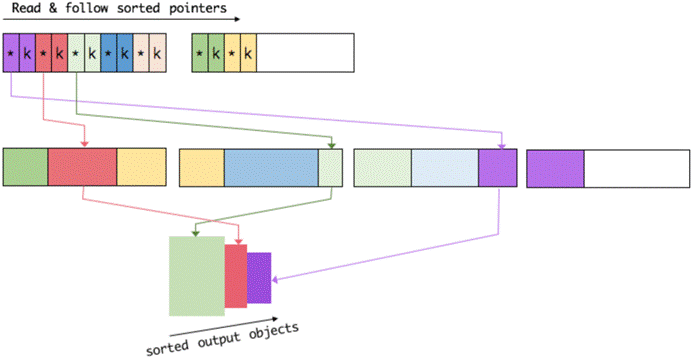
最后,访问排序后的数据,可以沿着排好序的key+pointer区域顺序访问,通过pointer找到对应的真实数据,并写到内存或外部
缓存友好的数据结构和算法
随着磁盘IO和网络IO越来越快,CPU逐渐成为了大数据领域的瓶颈。从 L1/L2/L3 缓存读取数据的速度比从主内存读取数据的速度快好几个量级。通过性能分析可以发现,CPU时间中的很大一部分都是浪费在等待数据从主内存过来上。如果这些数据可以从 L1/L2/L3 缓存过来,那么这些等待时间可以极大地降低,并且所有的算法会因此而受益。
在上面讨论中我们谈到的,Flink 通过定制的序列化框架将算法中需要操作的数据(如sort中的key)连续存储,而完整数据存储在其他地方。因为对于完整的数据来说,key+pointer更容易装进缓存,从而提高了基础算法的效率。这对于上层应用是完全透明的,可以充分享受缓存友好带来的性能提升。
走向堆外内存
Flink 基于堆内存的内存管理机制已经可以解决很多JVM现存问题了,为什么还要引入堆外内存?
启动超大内存(上百GB)的JVM需要很长时间,GC停留时间也会很长(分钟级)。使用堆外内存的话,可以极大地减小堆内存(只需要分配Remaining Heap那一块),使得 TaskManager 扩展到上百GB内存不是问题。
高效的 IO 操作。堆外内存在写磁盘或网络传输时是 zero-copy,而堆内存的话,至少需要 copy 一次。
堆外内存是进程间共享的。也就是说,即使JVM进程崩溃也不会丢失数据。这可以用来做故障恢复(Flink暂时没有利用起这个,不过未来很可能会去做)。
但是强大的东西总是会有其负面的一面,不然为何大家不都用堆外内存呢。
堆内存的使用、监控、调试都要简单很多。堆外内存意味着更复杂更麻烦。
Flink 有时需要分配短生命周期的 MemorySegment,这个申请在堆上会更廉价。
有些操作在堆内存上会快一点点。
Flink用通过ByteBuffer.allocateDirect(numBytes)来申请堆外内存,用 sun.misc.Unsafe 来操作堆外内存。在flink的源码中大量的 getXXX/putXXX 方法都是调用了 unsafe 方法去操作内存(这个内存包括堆外内存与堆内内存)。
另外,Flink的源码中,许多方法都被标记成了 final,两个子类也是 final 类型,为的也是优化JIT 编译器(java及时编译器),会提醒 JIT 这个方法是可以被去虚化和内联的。
7.对比Spark
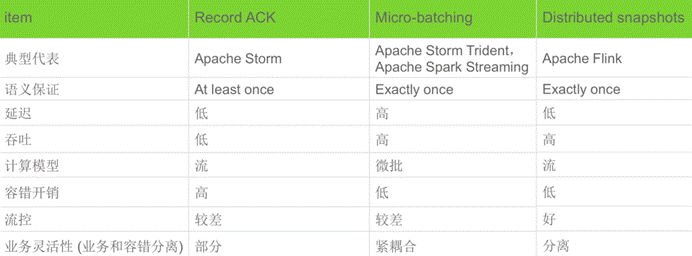
流式计算框架对比
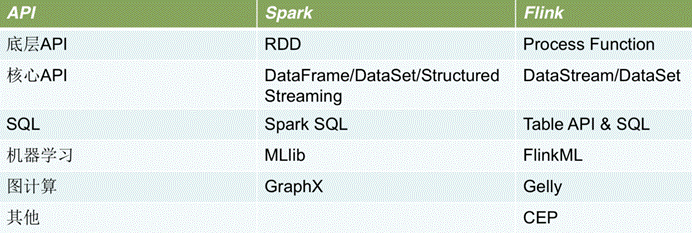
API对比
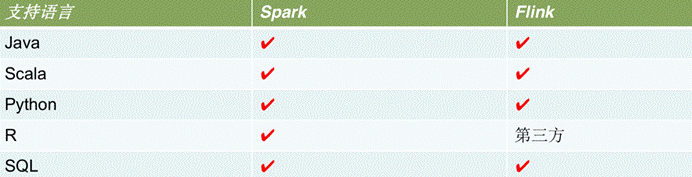
数据源对比
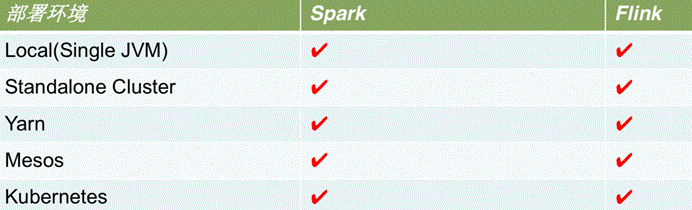
运行环境对比
社区对比
Spark 社区在规模和活跃程度上都是领先的,毕竟多了几年发展时间,同时背后的商业公司Databricks 由于本土优势使得Spark在美国的影响力明显优于Flink
而且作为一个德国公司,Data Artisans 想在美国扩大影响力要更难一些。不过 Flink 社区也有一批 稳定的支持者,达到了可持续发展的规模。
Spark社区活跃度比Flink高很多。
Flink 的中文社区在
目前spark和flink各有所长,spark基于内存的批量运算,flink高可靠的exactly-once的流式运算
还是那句话看你的应用场景是什么,从而选择哪个更适合
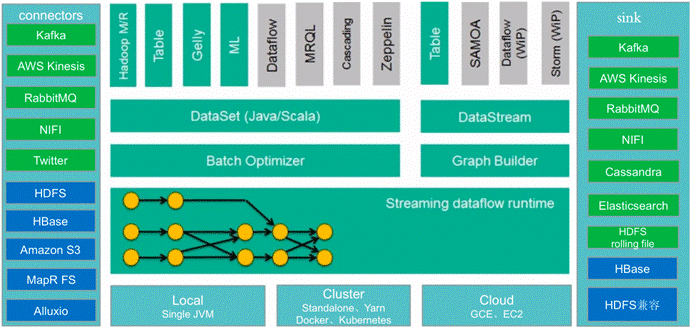
8.Flink生态
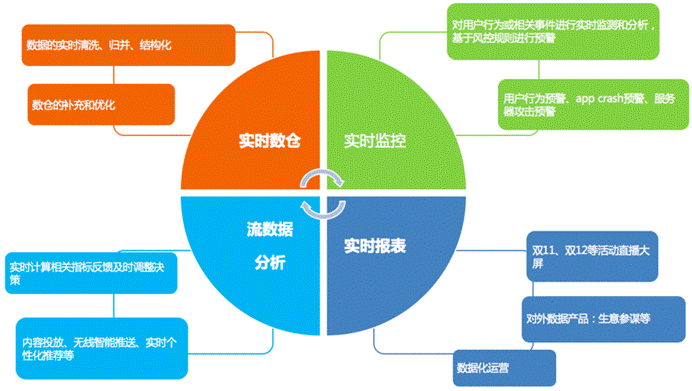
9.Flink应用场景
10.Flink的未来
• 批计算的突破、流处理和批处理无缝切换、界限越来越模糊、甚至混合
• Flink-SQL
• 完善Machine Learning 算法库,同时 Flink 也会向更成熟的机器学习、深度学习去集成(比如Tensorflow On Flink)

