
大数剧-flink-基础编程
Flink的API分层、开发环境搭建、基本开发流、架构与组件原理、并行度、任务执行计划、chains、SlotGroup与Slot共享
1.Flink的API分层
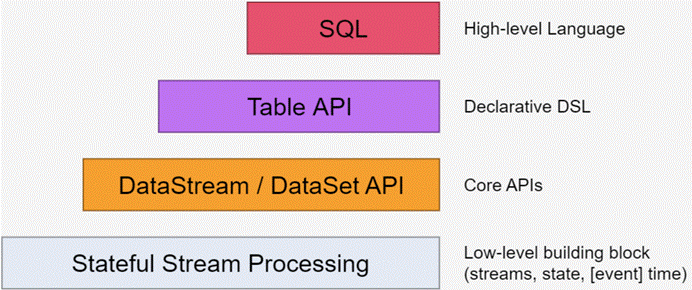
注:越底层API越灵活,越上层的API越轻便
Stateful Stream Processing
l 位于最底层, 是core API 的底层实现
l processFunction
l 利用低阶,构建一些新的组件或者算子
l 灵活性高,但开发比较复杂
Core API
l DataSet - 批处理 API
l DataStream –流处理 API
Table API & SQL
l SQL 构建在Table 之上,都需要构建Table 环境
l 不同的类型的Table 构建不同的Table 环境
l Table 可以与DataStream或者DataSet进行相互转换
l Streaming SQL不同于存储的SQL,最终会转化为流式执行计划
2.flink开发环境搭建
使用maven搭建开发环境
pom:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.myorg.quickstart</groupId>
<artifactId>quickstart</artifactId>
<version>0.1</version>
<packaging>jar</packaging>
<name>Flink Quickstart Job</name>
<url>http://www.myorganization.org</url>
<properties>
<java.version>1.8</java.version>
<scala.version>2.11</scala.version>
<flink.version>1.9.3</flink.version>
<parquet.version>1.10.0</parquet.version>
<hadoop.version>2.7.3</hadoop.version>
<fastjson.version>1.2.72</fastjson.version>
<redis.version>2.9.0</redis.version>
<mysql.version>8.0.22</mysql.version>
<log4j.version>1.2.17</log4j.version>
<slf4j.version>1.7.7</slf4j.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.build.scope>compile</project.build.scope>
<!-- <project.build.scope>provided</project.build.scope>-->
<mainClass>cn.zhanghub.Driver</mainClass>
</properties>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink的hadoop兼容 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink的hadoop兼容 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hadoop-compatibility_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink的java的api -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink streaming的java的api -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink的scala的api -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink streaming的scala的api -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink运行时的webUI -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- 使用rocksdb保存flink的state -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink操作hbase -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hbase_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink操作es -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch5_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink 的kafka -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink 写文件到HDFS -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-filesystem_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- mysql连接驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- redis连接 -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>${redis.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink操作parquet文件格式 -->
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>${parquet.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-hadoop</artifactId>
<version>${parquet.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- json操作 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
</dependency>
</dependencies>
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptors>
<descriptor>src/assembly/assembly.xml</descriptor>
</descriptors>
<archive>
<manifest>
<mainClass>${mainClass}</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.12</version>
<configuration>
<skip>true</skip>
<forkMode>once</forkMode>
<excludes>
<exclude>**/**</exclude>
</excludes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<encoding>${project.build.sourceEncoding}</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>
3.flink开发基本流程
1).DataStreamContext
getExecutionEnvironment 适合jar包与命令
- Jar
- cmd
createLocalEnvironment 适合本地测试开发
2).DataSet 与 DataStream
- 表示Flink app中的分布式数据集
- 包含重复的、不可变数据集
- DataSet有界、DataStream可以是无界
- 可以从数据源、也可以通过各种转换操作创建
3).flink编程套路
- 获取执行环境(execution environment)
- 加载/创建初始数据集
- 对数据集进行各种转换操作(生成新的数据集)
- 指定将计算的结果放到何处去
- 触发APP执行
4).flink的app计算方式和spark一样都是惰性的
- Flink APP都是延迟执行的
- 只有当execute()被显示调用时才会真正执行
- 本地执行还是在集群上执行取决于执行环境的类型
- 好处:用户可以根据业务构建复杂的应用,Flink可以整体进优化并生成执行计划
5).与sparkstreaming执行任务的不同之处:
- sparkstreaming是生成每小批的task放到executor放起来,任务跑完之后就退出,然后再生成新的task,executor再跑新的task,循环往复执行此动作。
- flink是生成task放到taskManager的taskSlot里面,然后这个task一直不退出,直到这个application整个退出它才退出。
计算模型:

- 定义源
- 写Transformations,就是写operators
- 定义输出
示例代码:
scala版:
package cn.zhanghub.flink.operator
import org.apache.flink.api.common.functions.FlatMapFunction
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.util.Collector
object SocketWordCount {
def main(args: Array[String]): Unit = {
//获得local运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration())
//定义socket的source源
val text: DataStream[String] = env.socketTextStream("localhost", 6666)
//scala开发需要加一行隐式转换,否则在调用operator的时候会报错,作用是找到scala类型的TypeInformation
import org.apache.flink.api.scala._
//写Transformations进行数据的转换
//定义operators,作用是解析数据,分组,并且求wordCount
// val wordCount: DataStream[(String, Int)] = text.flatMap(_.split(" ")).map((_, 1)).keyBy(_._1).sum(1)
//使用FlatMapFunction自定义函数来完成flatMap和map的组合功能
val wordCount: DataStream[(String, Int)] = text.flatMap(new FlatMapFunction[String, (String, Int)] {
override def flatMap(value: String, out: Collector[(String, Int)]) = {
val strings: Array[String] = value.split(" ")
for (s <- strings) {
out.collect((s, 1))
}
}
}).keyBy(_._1).sum(1)
//定义sink,打印数据到控制台
wordCount.print()
//定义任务的名称并运行
//注意:operator是惰性的,只有遇到execute才执行
env.execute("SocketWordCount")
}
}
java版:
package cn.zhanghub.operator;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
public class SocketWordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
DataStreamSource<String> socket = env.socketTextStream("localhost", 6666);
//1.lambda写法
// SingleOutputStreamOperator<String> flatMap = socket.flatMap((String value, Collector<String> out) -> {
// Arrays.stream(value.split(" ")).forEach(word -> {
// out.collect(word);
// });
// }).returns(Types.STRING);
//
// SingleOutputStreamOperator<Tuple2<String, Integer>> map = flatMap.map(f -> Tuple2.of(f, 1)).returns(Types.TUPLE(Types.STRING, Types.INT));
//
// SingleOutputStreamOperator<Tuple2<String, Integer>> sum = map.keyBy(0).sum(1);
//
// sum.print();
//2.function写法
// SingleOutputStreamOperator<String> flatMap = socket.flatMap(new FlatMapFunction<String, String>() {
// @Override
// public void flatMap(String value, Collector<String> out) throws Exception {
// String[] s = value.split(" ");
// for (String ss : s) {
// out.collect(ss);
// }
// }
// });
//
// SingleOutputStreamOperator<Tuple2<String, Integer>> map = flatMap.map(new MapFunction<String, Tuple2<String, Integer>>() {
// @Override
// public Tuple2<String, Integer> map(String value) throws Exception {
// return Tuple2.of(value, 1);
// }
// });
//
// SingleOutputStreamOperator<Tuple2<String, Integer>> sum = map.keyBy("f0").sum(1);
//
// sum.print();
//3.function组合写法
// SingleOutputStreamOperator<Tuple2<String,Integer>> flatMap = socket.flatMap(new FlatMapFunction<String, Tuple2<String,Integer>>() {
// @Override
// public void flatMap(String value, Collector<Tuple2<String,Integer>> out) throws Exception {
// String[] s = value.split(" ");
// for (String ss : s) {
// out.collect(Tuple2.of(ss,1));
// }
// }
// });
//
// SingleOutputStreamOperator<Tuple2<String, Integer>> sum = flatMap.keyBy(f -> f.f0).sum(1);
//
// sum.print();
//4.richfunction组合写法
// SingleOutputStreamOperator<Tuple2<String, Integer>> flatMap = socket.flatMap(new RichFlatMapFunction<String, Tuple2<String, Integer>>() {
//
// private String name = null;
//
// @Override
// public void open(Configuration parameters) throws Exception {
// name = "hainiu_";
// }
//
// @Override
// public void close() throws Exception {
// name = null;
// }
//
// @Override
// public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
// String[] s = value.split(" ");
// for (String ss : s) {
// System.out.println(getRuntimeContext().getIndexOfThisSubtask());
// out.collect(Tuple2.of(name + ss, 1));
// }
// }
// });
//
// SingleOutputStreamOperator<Tuple2<String, Integer>> sum = flatMap.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
// @Override
// public String getKey(Tuple2<String, Integer> value) throws Exception {
// return value.f0;
// }
// }).sum(1);
//
// sum.print();
//5.processfunction组合写法
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = socket.process(new ProcessFunction<String, Tuple2<String, Integer>>() {
private String name = null;
@Override
public void open(Configuration parameters) throws Exception {
name = "hainiu_";
}
@Override
public void close() throws Exception {
name = null;
}
@Override
public void processElement(String value, Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception {
// getRuntimeContext()
String[] s = value.split(" ");
for (String ss : s) {
System.out.println(getRuntimeContext().getIndexOfThisSubtask());
out.collect(Tuple2.of(name + ss, 1));
}
}
}).keyBy(0).process(new KeyedProcessFunction<Tuple, Tuple2<String, Integer>, Tuple2<String, Integer>>() {
private Integer num = 0;
@Override
public void processElement(Tuple2<String, Integer> value, Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception {
num += value.f1;
out.collect(Tuple2.of(value.f0,num));
}
});
sum.print();
env.execute();
}
}
4.Flink架构
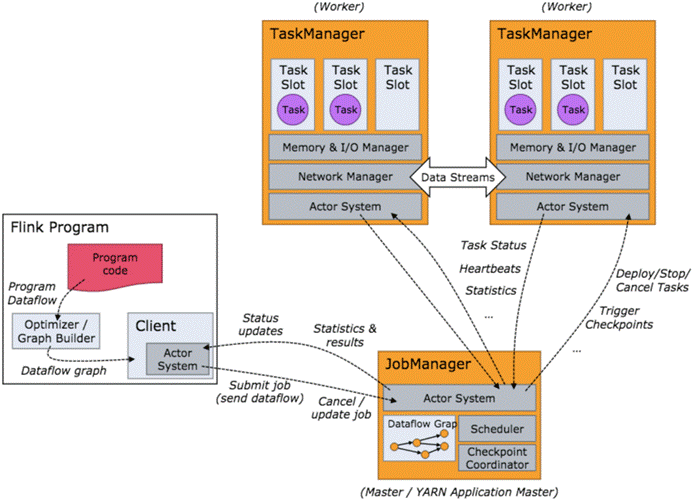
当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager,JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。
l Client 为提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交 Job 后,Client 可以结束进程(Streaming的任务),也可以不结束并等待结果返回。
l JobManager 主要负责从 Client 处接收到 Job 和 JAR 包等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskManager 去执行。
l TaskManager 在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个 Task,Task 为线程。从 JobManager 处接收需要部署的 Task,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。
l flnik架构中的角色间的通信使用Akka,数据的传输使用Netty
5.Task Slot
在上图中我们介绍了 TaskManager 是一个 JVM 进程,并会以独立的线程来执行一个task或多个subtask。为了控制一个 TaskManager 能接受多少个 task,Flink 提出了 Task Slot 的概念。
Flink 中的计算资源通过 Task Slot 来定义。每个 task slot 代表了 TaskManager 的一个固定大小的资源子集。例如,一个拥有3个slot的 TaskManager,会将其管理的内存平均分成三分分给各个 slot。将资源 slot 化意味着来自不同job的task不会为了内存而竞争,而是每个task都拥有一定数量的内存储备。需要注意的是,这里不会涉及到CPU的隔离,slot目前仅仅用来隔离task的内存。
通过调整 task slot 的数量,用户可以定义task之间是如何相互隔离的。每个 TaskManager 有一个slot,也就意味着每个task运行在独立的 JVM 中。每个 TaskManager 有多个slot的话,也就是说多个task运行在同一个JVM中。而在同一个JVM进程中的task,可以共享TCP连接(基于多路复用)和心跳消息,可以减少数据的网络传输。也能共享一些数据结构,一定程度上减少了每个task的消耗。
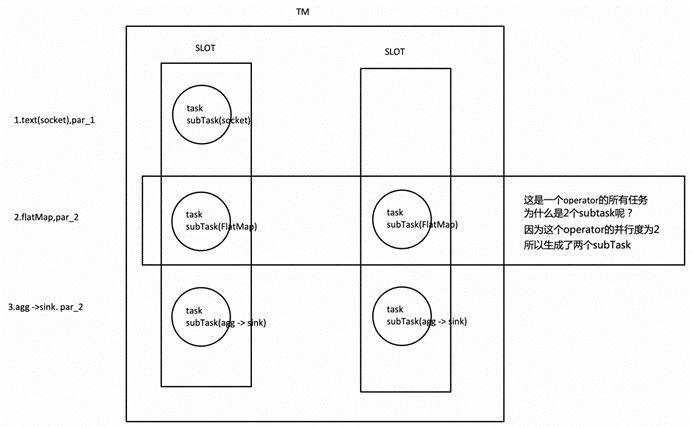
6.task的并行度
通过job的webUI界面查看任务的并行度
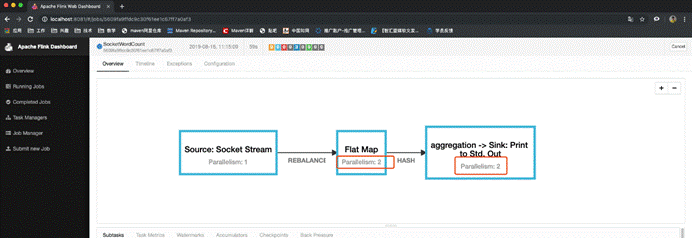
7.任务执行计划
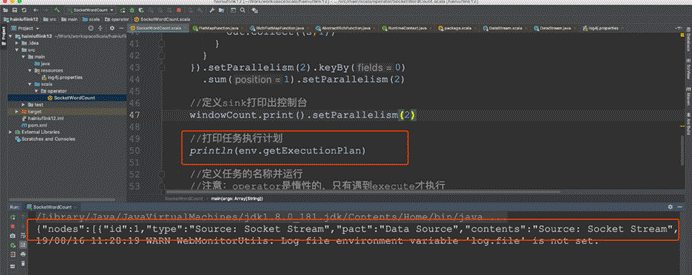
生成个json字符串然后粘贴在这里https://flink.apache.org/visualizer/会看到任务执行图

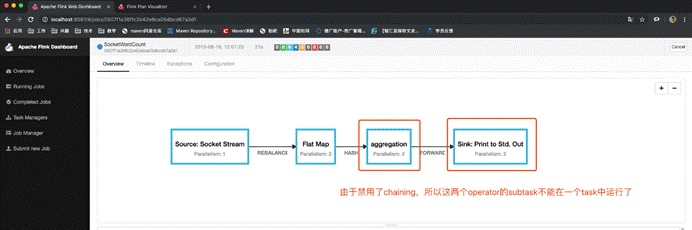
但这并不是最终在 Flink 中运行的执行图,只是一个表示拓扑节点关系的计划图,在 Flink 中对应了 SteramGraph。另外,提交拓扑后(并发度设为2)还能在 UI 中看到另一张执行计划图,如下所示,该图对应了 Flink 中的 JobGraph。

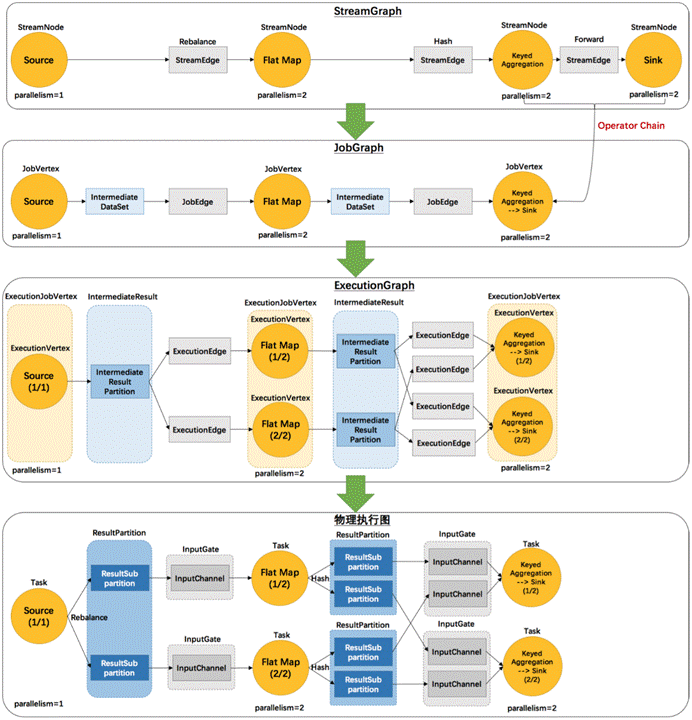
其实Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图
- StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
- JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
- ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
- 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
例如上文中的2个并发度(Source为1个并发度)的 SocketTextStreamWordCount 四层执行图的演变过程如下图所示:
那么 Flink 为什么要设计这4张图呢,其目的是什么呢?Spark 中也有多张图,数据依赖图以及物理执行的DAG。其目的都是一样的,就是解耦,每张图各司其职,每张图对应了 Job 不同的阶段,更方便做该阶段的事情。我们给出更完整的 Flink Graph 的层次图。
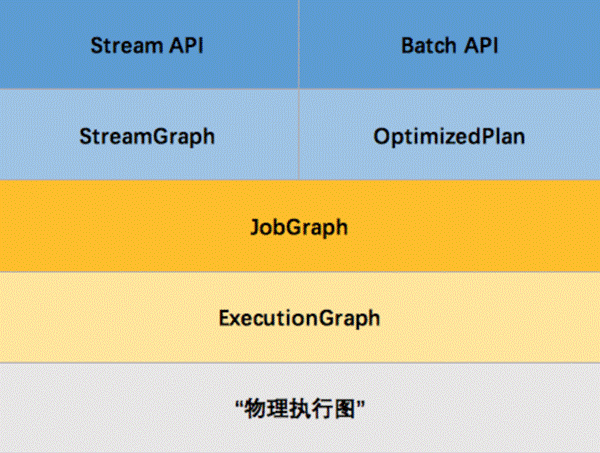
首先我们看到,JobGraph 之上除了 StreamGraph 还有 OptimizedPlan。OptimizedPlan 是由 Batch API 转换而来的。StreamGraph 是由 Stream API 转换而来的。为什么 API 不直接转换成 JobGraph?因为,Batch 和 Stream 的图结构和优化方法有很大的区别,比如 Batch 有很多执行前的预分析用来优化图的执行,而这种优化并不普适于 Stream,所以通过 OptimizedPlan 来做 Batch 的优化会更方便和清晰,也不会影响 Stream。JobGraph 的责任就是统一 Batch 和 Stream 的图,用来描述清楚一个拓扑图的结构,并且做了 chaining 的优化,chaining 是普适于 Batch 和 Stream 的,所以在这一层做掉。ExecutionGraph 的责任是方便调度和各个 tasks 状态的监控和跟踪,所以 ExecutionGraph 是并行化的 JobGraph。而“物理执行图”就是最终分布式在各个机器上运行着的tasks了。所以可以看到,这种解耦方式极大地方便了我们在各个层所做的工作,各个层之间是相互隔离的。
8.Operator Chains
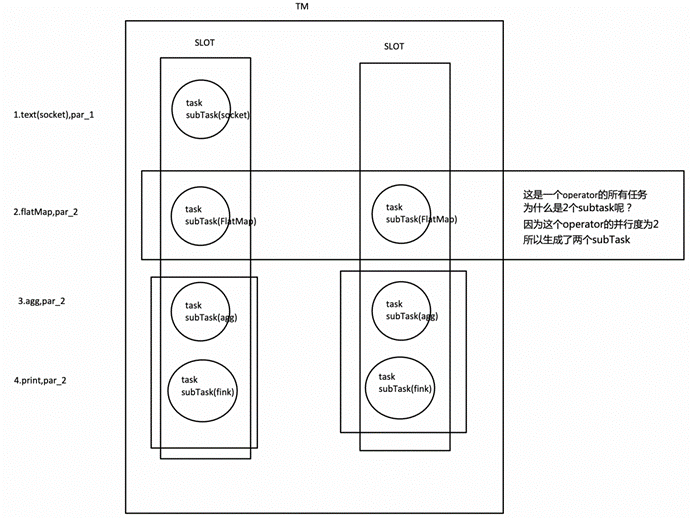
为了更高效地分布式执行,Flink会尽可能地将operator的subtask链接(chain)在一起形成task。每个task在一个线程中执行。将operators链接成task是非常有效的优化:它能减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,减少了延迟的同时提高整体的吞吐量。
我们仍以上面的 WordCount 为例,下面这幅图,展示了Source并行度为1,FlatMap、KeyAggregation、Sink并行度均为2,最终以5个并行的线程来执行的优化过程。
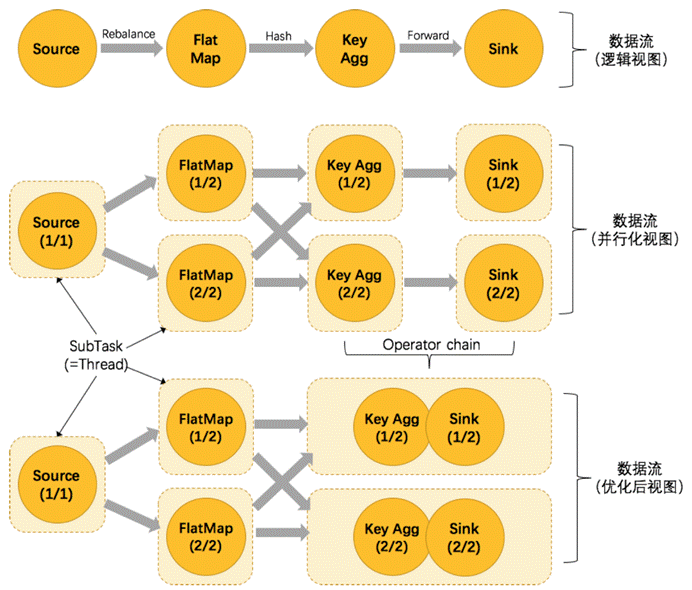
上图中将KeyAggregation和Sink两个operator进行了合并,因为这两个合并后并不会改变整体的拓扑结构。但是,并不是任意两个 operator 就能 chain 一起的。其条件还是很苛刻的:
上下游的并行度一致
下游节点的入度为1 (也就是说下游节点没有来自其他节点的输入)
上下游节点都在同一个 slot group 中(下面会解释 slot group)
下游节点的 chain 策略为 ALWAYS(可以与上下游链接,map、flatmap、filter等默认是ALWAYS)
上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source默认是HEAD)
- 上下游算子之间没有数据shuffle (数据分区方式是 forward)
- 用户没有禁用 chain
Operator chain的行为可以通过编程API中进行指定。可以通过在DataStream的operator后面(如someStream.map(..))调用startNewChain()来指示从该operator开始一个新的chain(与前面截断,不会被chain到前面)。或者调用disableChaining()来指示该operator不参与chaining(不会与前后的operator chain一起)。在底层,这两个方法都是通过调整operator的 chain 策略(HEAD、NEVER)来实现的。另外,也可以通过调用StreamExecutionEnvironment.disableOperatorChaining()来全局禁用chaining。
代码验证:
l operator禁用chaining
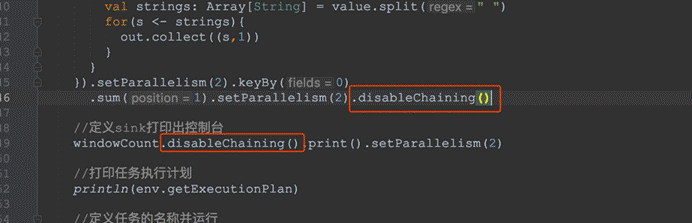
l 全局禁用chaining
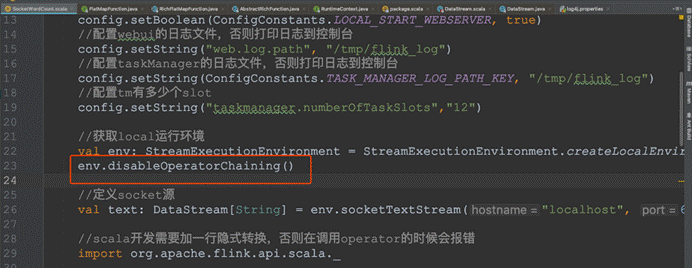
查看job的graph图
OperatorChain的优缺点:
那么 Flink 是如何将多个 operators chain在一起的呢?chain在一起的operators是如何作为一个整体被执行的呢?它们之间的数据流又是如何避免了序列化/反序列化以及网络传输的呢?下图展示了operators chain的内部实现:
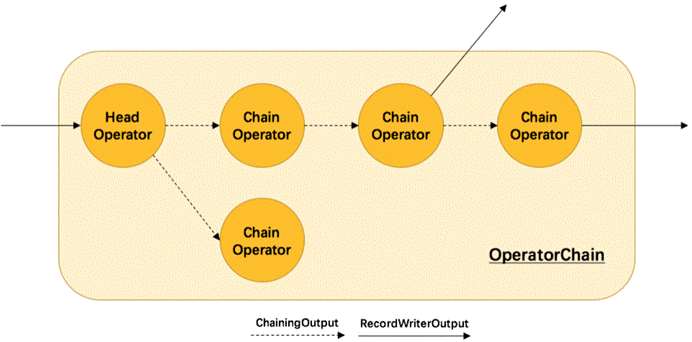
如上图所示,Flink内部是通过OperatorChain这个类来将多个operator链在一起形成一个新的operator。OperatorChain形成的框框就像一个黑盒,Flink 无需知道黑盒中有多少个ChainOperator、数据在chain内部是怎么流动的,只需要将input数据交给 HeadOperator 就可以了,这就使得OperatorChain在行为上与普通的operator无差别,上面的OperaotrChain就可以看做是一个入度为1,出度为2的operator。所以在实现中,对外可见的只有HeadOperator,以及与外部连通的实线输出,这些输出对应了JobGraph中的JobEdge,在底层通过RecordWriterOutput来实现。另外,框中的虚线是operator chain内部的数据流,这个流内的数据不会经过序列化/反序列化、网络传输,而是直接将消息对象传递给下游的 ChainOperator 处理,这是性能提升的关键点,在底层是通过 ChainingOutput 实现的
OperatorChain的优点总结:
- 减少线程切换
- 减少序列化与反序列化
- 减少数据在缓冲区的交换
- 减少延迟并且提高吞吐能力
OperatorChain的缺点总结:
- 可能会让N个比较复杂的业务跑在一个slot中,本来一个业务就慢,这发生这种情况就更慢了,所以可以通过startNewChain()/disableChaining()或全局禁用disableOperatorChaining()给分开
9.SlotSharingGroup 与 CoLocationGroup
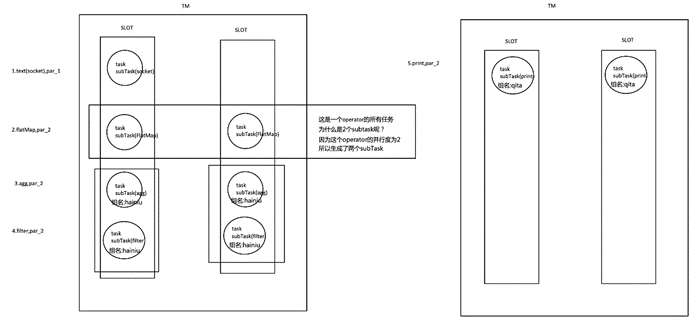
每一个 TaskManager 会拥有一个或多个的 task slot,每个 slot 都能跑由多个连续 task 组成的一个 pipeline,比如 MapFunction 的第n个并行实例和 ReduceFunction 的第n个并行实例可以组成一个 pipeline。
如上文所述的 WordCount 例子,5个Task没有solt共享的时候在TaskManager的slots中如下图分布,2个TaskManager,每个有3个slot:
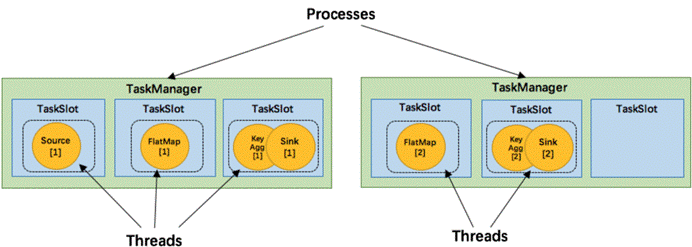
默认情况下,Flink 允许subtasks共享slot,条件是它们都来自同一个Job的不同task的subtask。结果可能一个slot持有该job的整个pipeline。允许slot共享有以下两点好处:
Flink 集群所需的task slots数与job中最高的并行度一致。
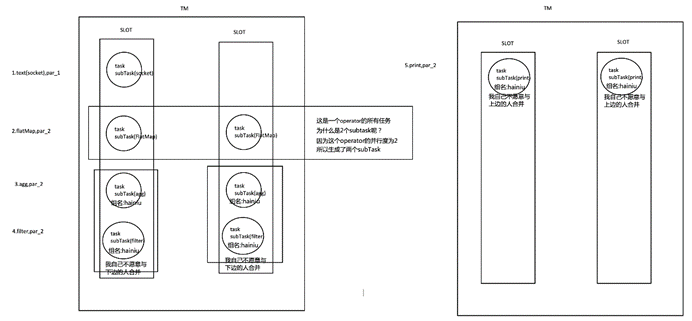
更容易获得更充分的资源利用。如果没有slot共享,那么非密集型操作source/flatmap就会占用同密集型操作 keyAggregation/sink 一样多的资源。如果有slot共享,将基线的2个并行度增加到6个,能充分利用slot资源,同时保证每个TaskManager能平均分配到相同数量的subtasks。
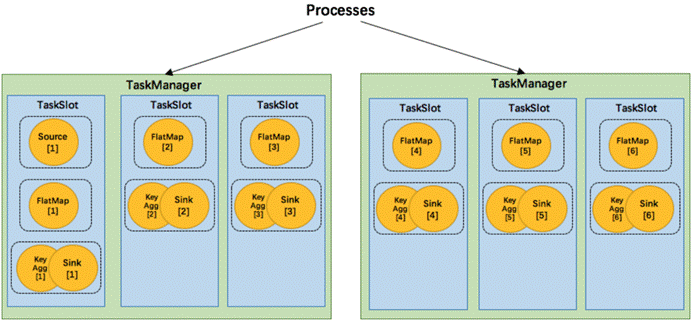
我们将 WordCount 的并行度从之前的2个增加到6个(Source并行度仍为1),并开启slot共享(所有operator都在default共享组),将得到如上图所示的slot分布图。该任务最终会占用6个slots(最高并行度为6)。其次,我们可以看到密集型操作 keyAggregation/sink 被平均地分配到各个 TaskManager。
SlotSharingGroup:
l SlotSharingGroup是Flink中用来实现slot共享的类,它尽可能地让subtasks共享一个slot。
l 保证同一个group的并行度相同的sub-tasks 共享同一个slots
l 算子的默认group为default(即默认一个job下的subtask都可以共享一个slot)
l 为了防止不合理的共享,用户也能通过API来强制指定operator的共享组,比如:someStream.filter(…).slotSharingGroup(“group1”);就强制指定了filter的slot共享组为group1。
l 怎么确定一个未做SlotSharingGroup设置的算子的Group是什么呢(根据上游算子的 group和自身是否设置group共同确定)
l 适当设置可以减少每个slot运行的线程数,从而整体上减少机器的负载
CoLocationGroup(强制):
l 保证所有的并行度相同的sub-tasks运行在同一个slot
l 主要用于迭代流(训练机器学习模型)
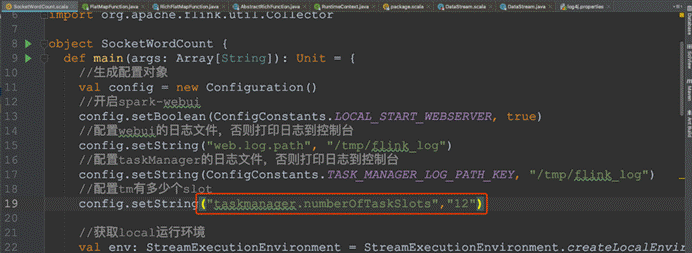
代码验证:
l 设置本地开发环境tm的slot数量
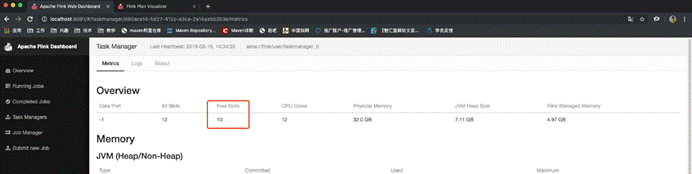
l 设置最后的operator使用新的group
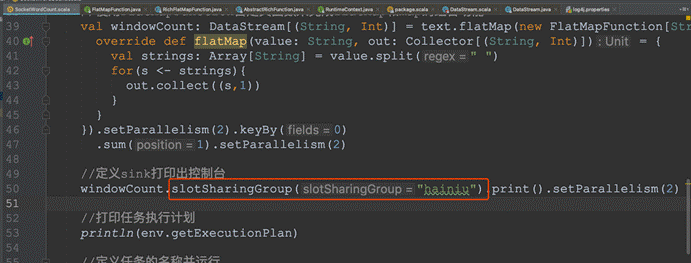
l 由于不和前面的operator在一个group,无法进行slot的共享,所以最后的operator占用了其它slot
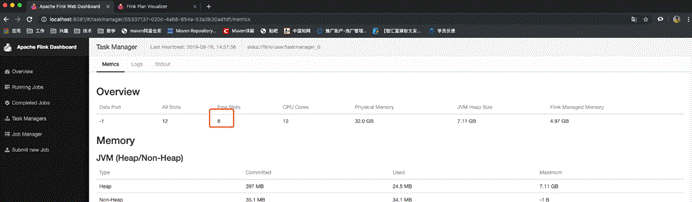
· 为什么占用了两个呢?
- 因为不同组,与上面的default不能共享slot,组间互斥
- 同组中的同一个operator的subtask不能在一个slot中,由于operator的并行度是2,所以占用了两个槽位,subtask组内互斥
原理与实现
那么多个tasks(或者说operators)是如何共享slot的呢?
关于Flink调度,有两个非常重要的原则我们必须知道:
- 同一个operator的各个subtask是不能呆在同一个SharedSlot中的,例如FlatMap[1]和FlatMap[2]是不能在同一个SharedSlot中的。
- Flink是按照拓扑顺序从Source一个个调度到Sink的。例如WordCount(Source并行度为1,其他并行度为2),那么调度的顺序依次是:Source -> FlatMap[1] -> FlatMap[2] -> KeyAgg->Sink[1] -> KeyAgg->Sink[2]。假设现在有2个TaskManager,每个只有1个slot(为简化问题),那么分配slot的过程如图所示:
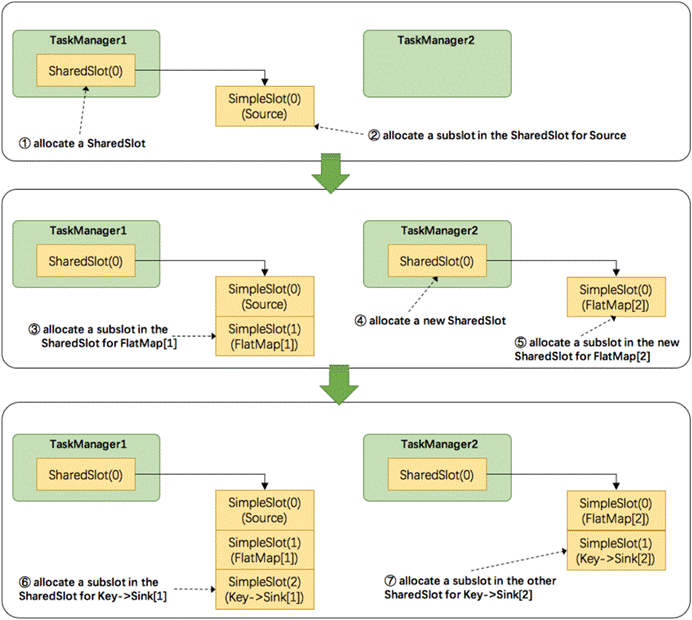
注:图中 SharedSlot 与 SimpleSlot 后带的括号中的数字代表槽位号(slotNumber)
- 为Source分配slot。首先,我们从TaskManager1中分配出一个SharedSlot。并从SharedSlot中为Source分配出一个SimpleSlot。如上图中的①和②。
- 为FlatMap[1]分配slot。目前已经有一个SharedSlot,则从该SharedSlot中分配出一个SimpleSlot用来部署FlatMap[1]。如上图中的③。
- 为FlatMap[2]分配slot。由于TaskManager1的SharedSlot中已经有同operator的FlatMap[1]了,我们只能分配到其他SharedSlot中去。从TaskManager2中分配出一个SharedSlot,并从该SharedSlot中为FlatMap[2]分配出一个SimpleSlot。如上图的④和⑤。
- 为Key->Sink[1]分配slot。目前两个SharedSlot都符合条件,从TaskManager1的SharedSlot中分配出一个SimpleSlot用来部署Key->Sink[1]。如上图中的⑥。
- 为Key->Sink[2]分配slot。TaskManager1的SharedSlot中已经有同operator的Key->Sink[1]了,则只能选择另一个SharedSlot中分配出一个SimpleSlot用来部署Key->Sink[2]。如上图中的⑦。
最后Source、FlatMap[1]、Key->Sink[1]这些subtask都会部署到TaskManager1的唯一一个slot中,并启动对应的线程。FlatMap[2]、Key->Sink[2]这些subtask都会被部署到TaskManager2的唯一一个slot中,并启动对应的线程。从而实现了slot共享。
Flink中计算资源的相关概念以及原理实现。最核心的是 Task Slot,每个slot能运行一个或多个task。为了拓扑更高效地运行,Flink提出了Chaining,尽可能地将operators chain在一起作为一个task来处理。为了资源更充分的利用,Flink又提出了SlotSharingGroup,尽可能地让多个task共享一个slot。
10.如何计算一个应用需要多少slot
· 不设置SlotSharingGroup,就是不设置新的组大家都为default组。(应用的最大并行度)
· 设置SlotSharingGroup ,就是设置了新的组,比如下图有两个组default和test组(所有SlotSharingGroup中的最大并行度之和)
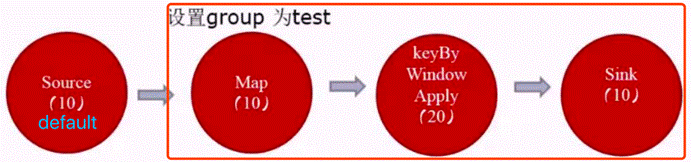
由于source和map之后的operator不属于同一个group,所以source和它们不能在一个solt中运行,而这里的source的default组的并行度是10,test组的并行度是20,所以所需槽位一共是30
11.运行时概念总结
· Job
· Operator
· Parallelism
· Task 与 subtask(线程)
· Chain
· SlotSharingGroup
· CoLocationGroup
· Jobmanger
· TaskManger
· TaskManager Slots

