
大数剧-hadoop-基本介绍
1、Hadoop的整体框架
Hadoop由HDFS、MapReduce、HBase、Hive和ZooKeeper等成员组成,其中最基础最重要元素为底层用于存储集群中所有存储节点文件的文件系统HDFS(Hadoop Distributed File System)来执行MapReduce程序的MapReduce引擎。即(分布式存储hdfs+分布式计算MapperReduce)
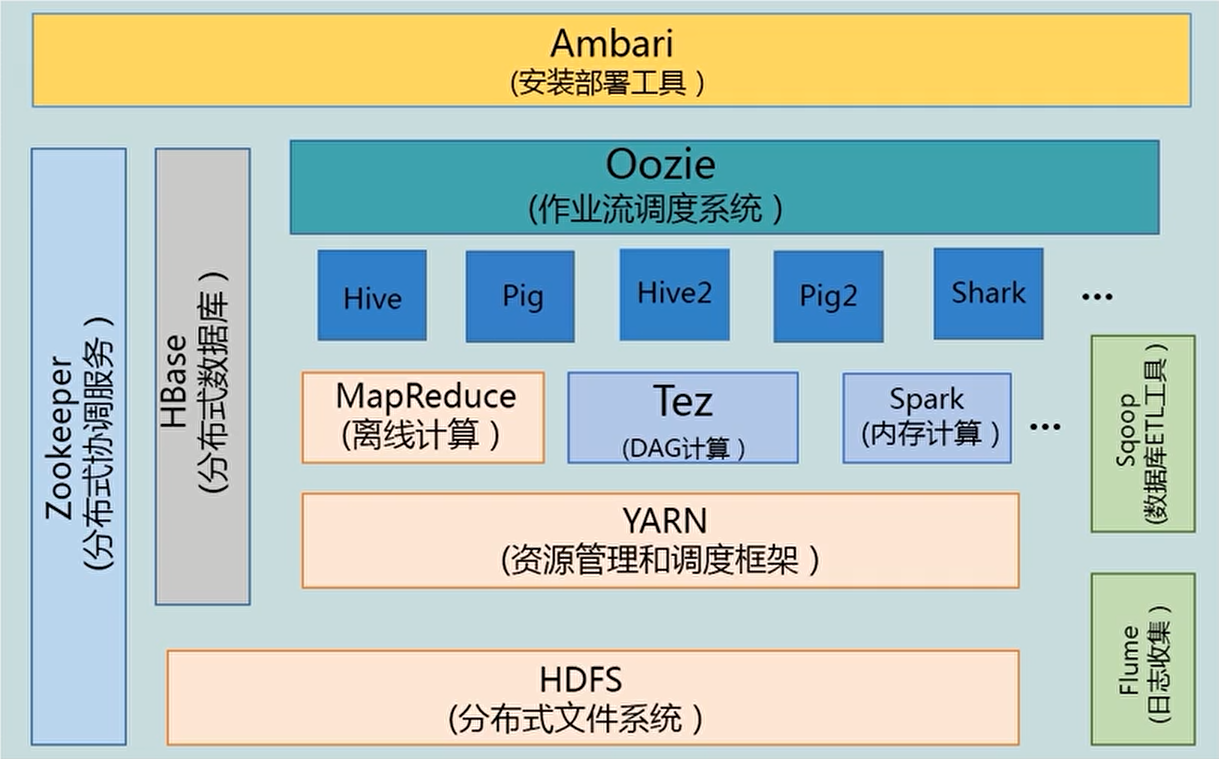
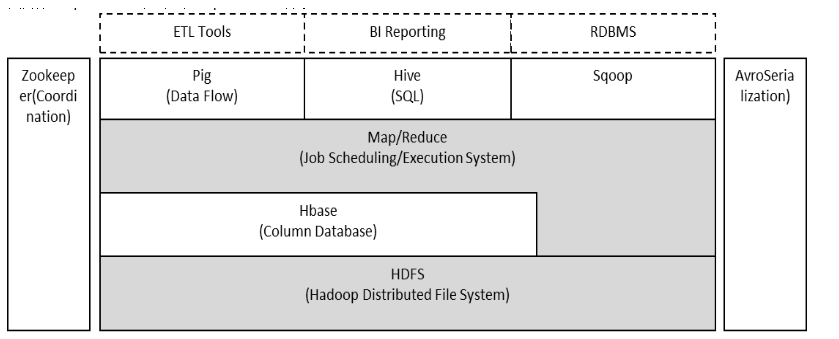
(1)Pig是一个基于Hadoop的大规模数据分析平台,Pig为复杂的海量数据并行计算提供了一个简单的操作和编程接口;
(2)Hive是基于Hadoop的一个工具,提供完整的SQL查询,可以将sql语句转换为MapReduce任务进行运行;
(3)ZooKeeper:高效的,可拓展的协调系统,存储和协调关键共享状态;
(4)HBase是一个开源的,基于列存储模型的分布式数据库;
(5)HDFS是一个分布式文件系统,有着高容错性的特点,适合那些超大数据集的应用程序;
(6)MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
Hadoop项目结构
| 组件 | 功能 |
|---|---|
| HDFS | 分布式文件系统 |
| MapReduce | 分布式并行编程模型 |
| YARN | 资源管理和调度器 |
| Tez | 运行在YARN之上的下一代Hadoop查询处理框架 |
| Hive | Hadoop上的数据仓库 |
| HBase | Hadoop上的非关系型的分布式数据库 |
| Pig | 一个基于Hadoop的大规模数据分析平台,提供类似SQL的查询语言Pig Latin |
| Sqoop | 用于在Hadoop与传统数据库之间进行数据传递 |
| Oozie | Hadoop上的工作流管理系统 |
| Zookeeper | 提供分布式协调一致性服务 |
| Storm | 流计算框架 |
| Flume | 一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统 |
| Ambari | Hadoop快速部署工具,支持Apache Hadoop集群的供应、管理和监控 |
| Kafka | 一种高吞吐量的分布式发布订阅消息系统,可以处理消费者规模的网站中的所有动作流数据 |
| Spark | 类似于Hadoop MapReduce的通用并行框架 |
Hadoop框架中最核心的设计是为海量数据提供存储的HDFS和对数据进行计算的MapReduce
MapReduce的作业主要包括:
-(1)从磁盘或从网络读取数据,即IO密集工作;
-(2)计算数据,即CPU密集工作
Hadoop集群的整体性能取决于CPU、内存、网络以及存储之间的性能平衡。因此运营团队在选择机器配置时要针对不同的工作节点选择合适硬件类型
一个基本的Hadoop集群中的节点主要有
NameNode:负责协调集群中的数据存储
DataNode:存储被拆分的数据块
JobTracker:协调数据计算任务
TaskTracker:负责执行由JobTracker指派的任务
SecondaryNameNode:帮助NameNode收集文件系统运行的状态信息

