
大数剧-storm-进阶
Storm集群的框架
Storm集群遵循主/从( master/slave)结构,和Hadoop等分布式计算技术类似,语义上稍有不同。主/从结构中,通常有一个配置中静态指定或运行时动态选举出的主节点。
Storm使用前一种实现方式。主/从结构中因为引人了单点故障的风险而被诟病,因此解释Storm的主节点是半容错的。
Storm集群由一个主节点(称为nimbus)和一个或者多个工作节点(称为supervisor)组成。在nimbus和supervisor节点之外,Storm 还需要一个Apache ZooKeeper的实例,
ZooKeeper实例本身可以由一个或者多个节点组成。如图下图所示。
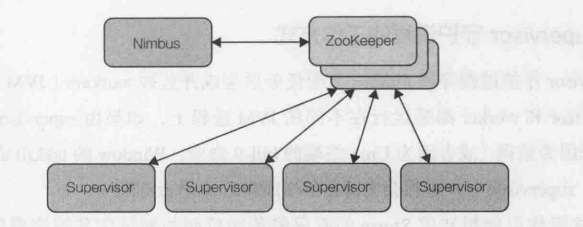
nimbus和supervisor都是Storm提供的后台守护进程,可以共存在同一台机器上。实际上,可以建立一个单节点伪集群,把nimbus、supervisor 和ZooKeeper进程都运行在同
一台机器上。
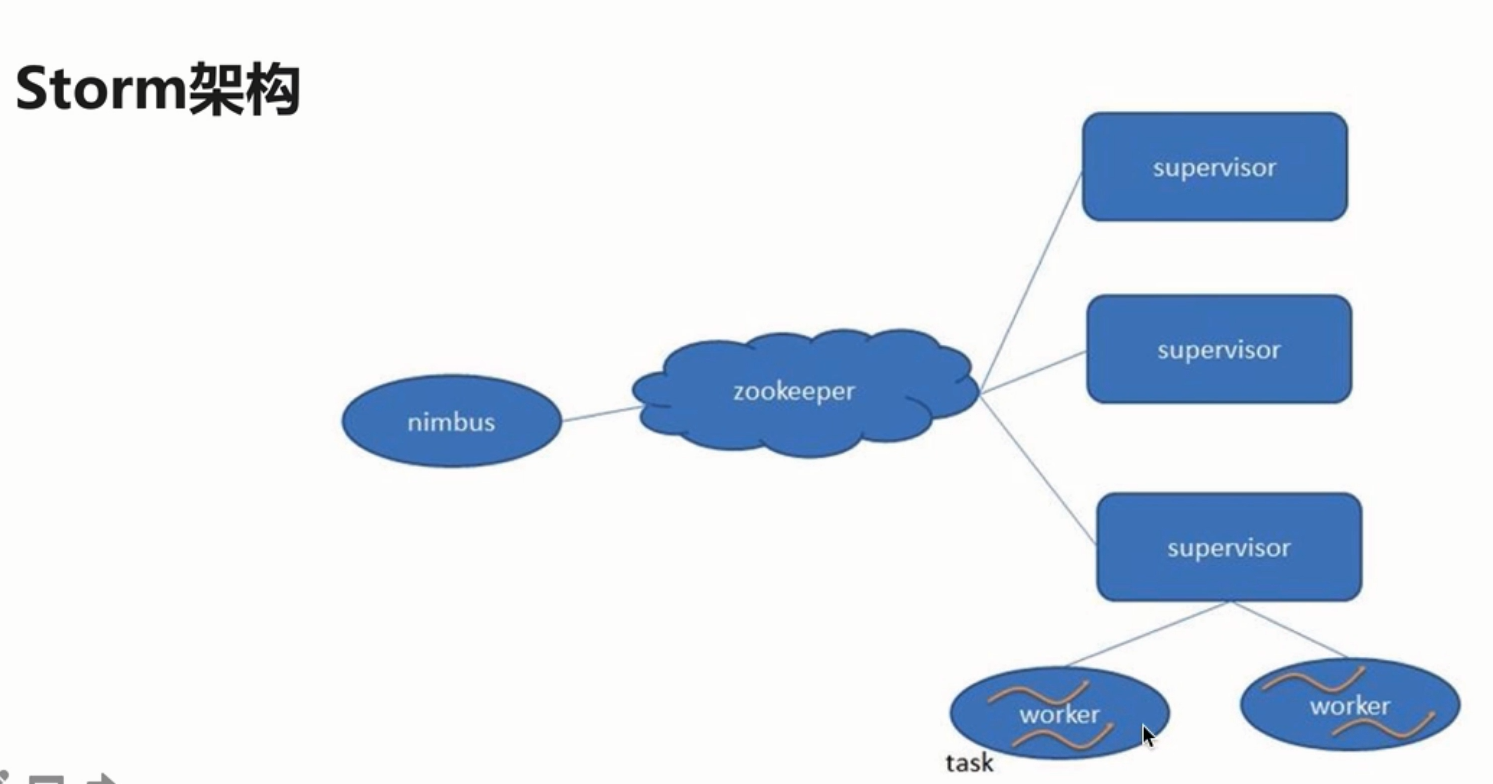
类似于Hadoop的架构,主从(Master/Slave)
Nimbus: 主
集群的主节点,负责任务(task)的指派和分发、资源的分配Supervisor: 从
可以启动多个Worker,具体几个呢?可以通过配置来指定
一个Topology可以运行在多个Worker之上,也可以通过配置来指定集群的从节点,(负责干活的),负责执行任务的具体部分启动和停止自己管理的Worker进程
无状态,在他们上面的信息(元数据)会存储在ZK中
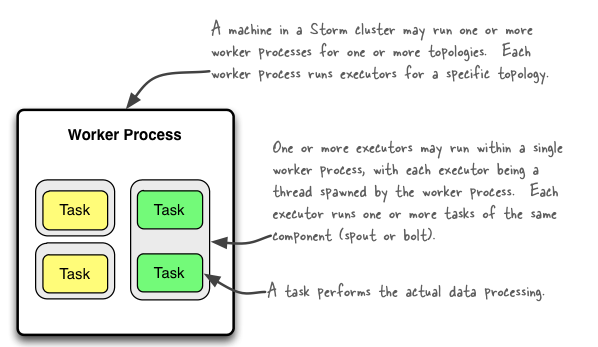
Worker: 运行具体组件逻辑(Spout/Bolt)的进程
task:
Spout和Bolt
Worker中每一个Spout和Bolt的线程称为一个Taskexecutor: spout和bolt可能会共享一个线程
nimbus守护进程
nimbus守护进程的主要职责是管理,协调和监控在集群上运行的topology。包括topology的发布,任务指派,事件处理失败时重新指派任务。
将topology发布到Storm集群,将预先打包成jar文件的topology和配置信息提交( submitting)到nimbus服务器上。一旦nimbus接收到了topology 的压缩包,会将jar
包分发到足够数量的supervisor节点上。当supervisor节点接收到了topology压缩文件,nimbus就会指派task ( bolt和spout实例)到每个supervisor 并且发送信号指示supervisoer生成足够的worker来执行指派的task。
nimbus记录所有supervisor节点的状态和分配给它们的task。如果nimbus发现某个supervisor没有上报心跳或者已经不可达了,它会将故障supervisor分配的task 重新分配到集群中的其他supervisor节点。
前面提到过,严格意义上讲nimbus不会引起单点故障。这个特性是因为nimubs并不参与topology的数据处理过程,它仅仅是管理topology的初始化,任务分发和进行监控。
实际上,如果nimbus守护进程在topology运行时停止了,只要分配的supervisor和worker健康运行,topology 一直继续数据处理。要注意的是,在nimbus已经停止的情况
下supervisor异常终止,因为没有nimbus守护进程来重新指派失败这个终止的supervisor的任务,数据处理就会失败。
Zookeeper
ZooKeeper使用一个简单的操作原语集合和分组服务,在分布式环境下提供了集中式的信息维护管理服务。
它是一种简单但功能强大的分布式同步机制,允许客户端的应用程序监控或者订阅数据集中的部分数据,当数据产生,更新或者修改时,客户端都会收到通
知。
使用常见的ZooKeeper模式或方法,开发者可以实现分布式计算所需要的很多种机制,比如Leader选举,分布式锁和队列。Storm主要使用ZooKeeper来协调一个集群中的状态信息,比如任务的分配情况,
worker的状态,supervisor 之间的nimbus的拓扑度量。nimbus 和supervisor节点之间的通信主要是结合ZooKeeper的状态变更通知和监控通知来处理的。
Storm对ZooKeeper的使用相对比较轻量化,不会造成很重的资源负担。对于重量级的数据传输操作,比如发布topology时传输jar包,Storm 依赖Thirft(RPC)进行通信。
Storm的DRPC服务工作机制
Storm应用中的一个常见模式期望将Storm的并发性和分布式计算能力应用到“请求-响应”范式中。一个客户端进程或者应用提交了一个请求并同步地等待响应。这样的范式
可能看起来和典型topology的高异步性、长时间运行的特点恰恰相反,Storm 具有事务处理的特性来实现这种应用场景,如图所示。
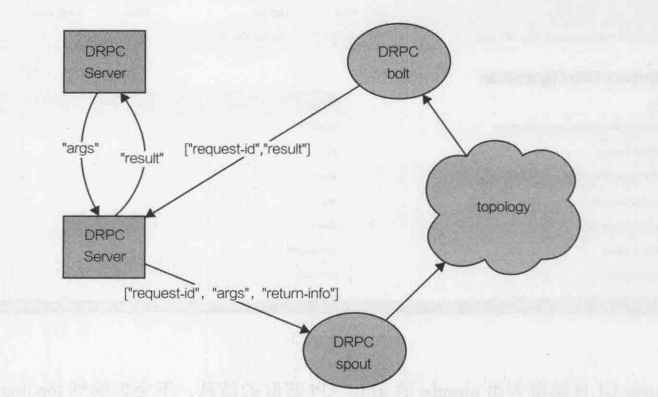
为了实现这个功能,Storm将额外的服务(StormDRPC)以及spout和bolt整合在-起工作,提供了可扩展的分布式RPC能力。
DRPC功能是完全是可选的,当Storm集群中的应用有使用这个功能时,DRPC服务节点才是必须的。
Storm UI
Storm UI也是可选功能,非常有用,会提供一个基于 Web的GUI来监控Storm集群,对正在运行的topology有一定的管理功能。Storm UI提供了已经发布的topology的统计信
息,对监控Storm集群的运转和topology的功能有很大帮助,如图。
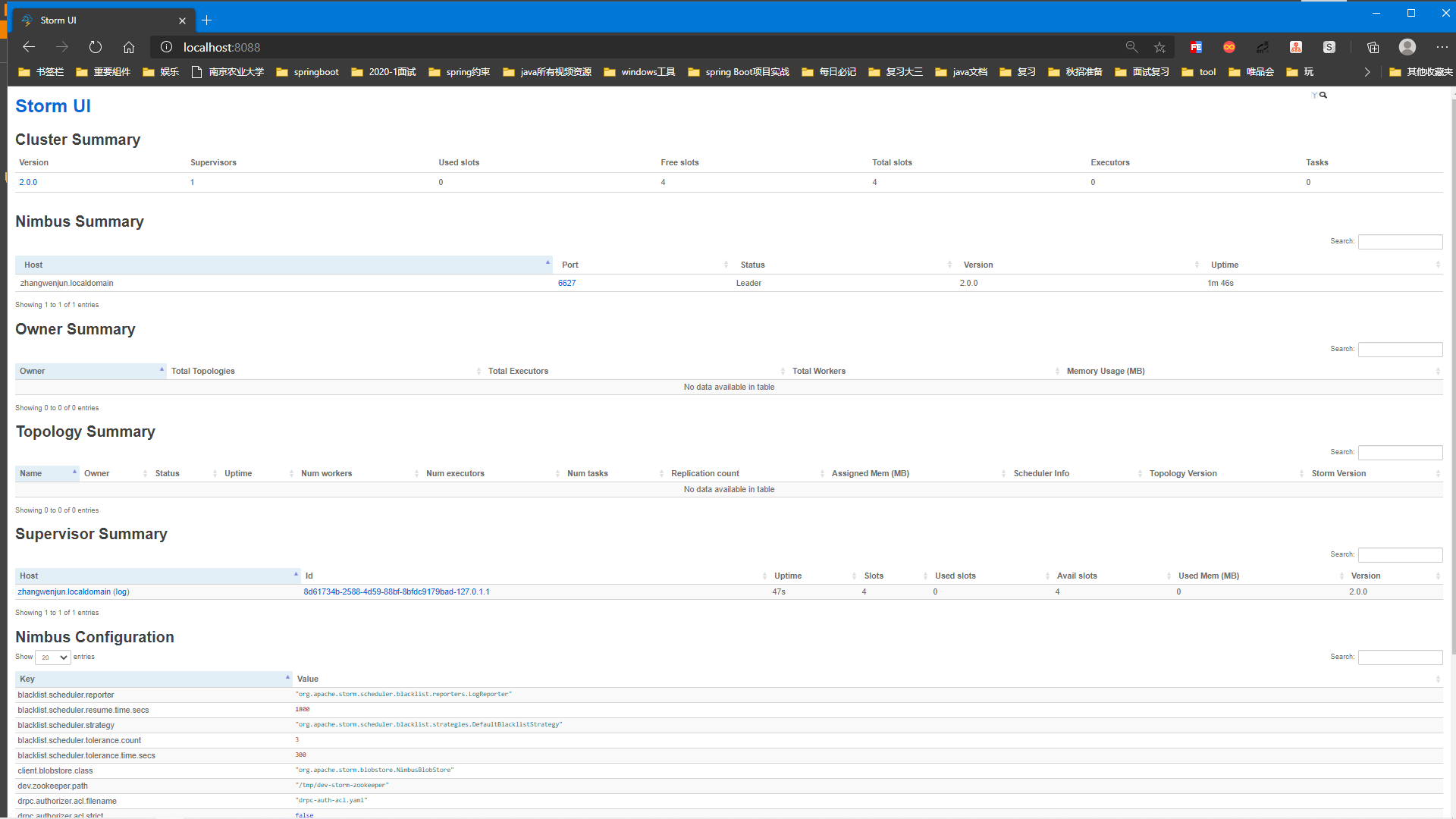
StormUI只能报告由nimubs的thiftAPI获取的信息,不会影响到topology上其他功能。StormUI可以随时开关而不影响任何topology的运行,在那里它完全是无状态
的。它还可以用配置来进行一些简单的管理功能,如开启、停止、暂停和重新均衡负载topology。
Stor 并行度
| 前缀 | 分类 | 前缀 | 分类 |
|---|---|---|---|
| storm.* | 通用配置 | supervisor.* | Supervisor配置 |
| nimbus.* | Nimbus配置 | worker.* | Worker配置 |
| ui.* | StormUI配置 | zmq.* | ZeroMQ配置 |
| drpc.* | DRPC服务配置 | topology.* | Topology配置 |
- nimbus.childopts(default: “-Xms1024m” ):这项JVM的配置会添加在启动nimbus守护进程的Java 命令行中。
- ui.port(default:8080): 这项配置指定了Storm UI的Web服务器监听的端口。
- ui.childopts(default: “-Xms1024m”) :这项JVM配置会添加在Storm UI服务启动的Java命令行中。
- supervisor.childopts(default: “ -Xms768m” ):这个JVM选项会添加在Supervisor启动的Java命令行中。
- worker.childopts(default: “-Xms768m” ):这个JVM选项会添加在启动worker进程的Java命令行中。
- tog.mssge.timeout. secs(default:30):这个配置项设定了一个tuple树需要应答最大时间秒数限制,超过这个时间的认为已经执行失败(超时)。这个值设置得太小可能会导致tuple反复重新发送。当这个选项生效时,spout 必须设定来发送锚定的tuple。
- topology.max.spout.pending(default:null): 在默认值null的时候,每当spout产生了新的tuple,Storm会立即将tuple向后端数据流发送。由于下游bolt执行可能有延迟,默认的数据发送行为可能导致topology过载,从而导致消息处理超时。将本选项设置为非null大于0的数字时,Storm会暂停发送tuple到数据流直到发送出去的tuple小于这个数字,起到了对spout限速的作用。这项配置和topology.message.timeoutsecs一起,是调节topology性能的最重要的两个参数。
- topology.enable. message.timeouts(default:ture):这个选项用来设定锚定的tuple的超时时间。如果设置为false, 则锚定的tuple不会超时。谨慎使用这个选项,将本项配置设置为flase 之前,考虑改变topology.message.timeout.secs.本项配置生效后,spout必须配置为发送锚定tuple。
Storm 后台进程命令 (关闭当前会话将会关闭该进程)
Storm的守护进程用来启动Storm服务,应该在被监督模式下启动,这样,程序如果有异常失败,服务就可以重启。在启动时,Storm 守护程序从 $STORM_HOME/conf/storm.yaml中读取配置。这个配置文件中的任何配置项都会重新定义内置的默认配置。(如果要在后台运行,命令后面可加上 &,如:storm nimbus & (这种方式关闭当前会话将会关闭该进程))
- Nimbus
用法: storm nimbus &
这个命令启动nimbus后台进程 - Supervisor
用法: storm supervisor &
这个命令启动supervisor后台进程 - UI
用法: storm ui &
这个命令启动StormUI的后台进程,提供了一个web的UI界面用来监控Storm集群。 - DRPC
用法: storm drpc &
这个命令启动一个DRPC服务后台进程
Storm部署条件
Storm部署的前置条件
- jdk7+
- python2.6.6+
我使用的Storm版本是:2.0.0
Storm部署
下载
解压到/usr/local
修改文件名为storm
添加到系统环境变量:~/.bashrc
export STORM_HOME=/usr/local/storm
export PATH=$STORM_HOME/bin:$PATH
使其生效:
source ~/.bashrc
目录结构
-bin
-examples
-conf
-lib
Storm启动
$STORM_HOME/bin/storm #如何使用 执行storm就能看到很多详细的命令提示:
command &在后台执行,如果未指定输出文件,依然会输出到当前窗口屏幕,且关闭会话时会结束该进程nohup command &如果以exit方式退出,不会结束该进程,切文件默认不会输出到屏幕
启动自带zk
storm dev-zookeeper #启动自带zk
nohup storm dev-zookeeper & #前台启动
jps : dev_zookeepernimbus 启动主节点
nohup storm nimbus &supervisor 启动从节点
nohup storm supervisor &ui 启动UI界面
nohup storm ui &logviewer 启动日志查看服务
nohup storm logviewer &注意事项
1) 为什么是4个slot
2) 为什么有2个Nimbus
Storm如何运行自己开发的应用程序呢?
Syntax: storm jar topology-jar-path class args0 args1 args2
storm jar /home/hadoop/lib/storm-1.0.jar com.imooc.bigdata.ClusterSumStormTopology问题: 3个executor,那么页面就看到spout1个和bolt1个,那么还有一个去哪了?
如何修改将跑在本地的storm toplogy改成运行在集群上的
StormSubmitter.submitTopology(topoName,new Config(), builder.createTopology());
storm 其他命令的使用
list
Syntax: storm list
List the running topologies and their statuses.停止作业
kill
Syntax: storm kill topology-name [-w wait-time-secs]如何停止集群
hadoop: stop-all.sh
kill -9 pid,pid....主要常用命令:
nimbus 启动主节点
nohup sh storm nimbus &supervisor 启动从节点
nohup sh storm supervisor &ui 启动UI界面
nohup sh storm ui &logviewer 启动日志查看服务
nohup sh storm logviewer &运行文件
storm jar /mnt/c/Users/user/Desktop/storm-1.0-SNAPSHOT.jar cn.zhanghub.bigdata.storm.sum.SumTopologyStorm 周边框架
logstash && kafka
logstash 和 kafka 的版本一定要按照logstash的要求选择(这里是logstash 2.4.1,kafka是kafka 2.11-0.9.0)
下载解压安装、配置path
kafka 2.11-0.9.0
中文文档 (文档有错,看时注意)
https://kafka.apachecn.org/quickstart.html#quickstart_send
开启zookeeper
zkServer.sh start开启kafka
kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties创建一个topic
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic logstash_topic查看所有topic
kafka-topics.sh --list --zookeeper localhost:2181开启一个生产者
kafka-console-producer.sh --broker-list localhost:9092 --topic logstash_topic开启一个消费者
kafka-console-consumer.sh --zookeeper localhost:2181 --topic logstash_topic --from-beginninglogstash 2.4.1
执行脚本文件
logstash -f /usr/local/logstash/conf/mykafka.conf
mykafka.conf:
```shell
input {
file {
path => "/usr/local/logstash/test/logstash.txt"
}
}
output {
kafka {
topic_id => "logstash_topic"
bootstrap_servers => "localhost:9092"
codec => "json"
batch_size => 1
}
}
```
